 Zabbix 下载
Zabbix 下载 Zabbix 手册
Zabbix 手册 Zabbix合作伙伴地图
Zabbix合作伙伴地图 成为我们的合作伙伴
成为我们的合作伙伴
 订阅系统登录
订阅系统登录案例|九江银行Zabbix监控系统实践
\ | /
★
生命周期内定期升级Sever和Proxy的小版本。一直没有查出什么原因,最后升级了小版本,升级完之后就完美解决了。
—— 张义 九江银行信息科技部 高级系统管理员
Zabbix监控平台建设历程
九江银行Zabbix监控系统实践,共分为三个部分:
1.Zabbix监控平台的建设历程
2.Zabbix实践经验分享
3.对未来监控的展望。
项目背景
建立新的一体化基础监控平台。为适应数字化转型的需要、新技术发展的需要及业务连续性的需要。以提高运维自动化、智能化的水平,提高安全生产运营的水平和能力。
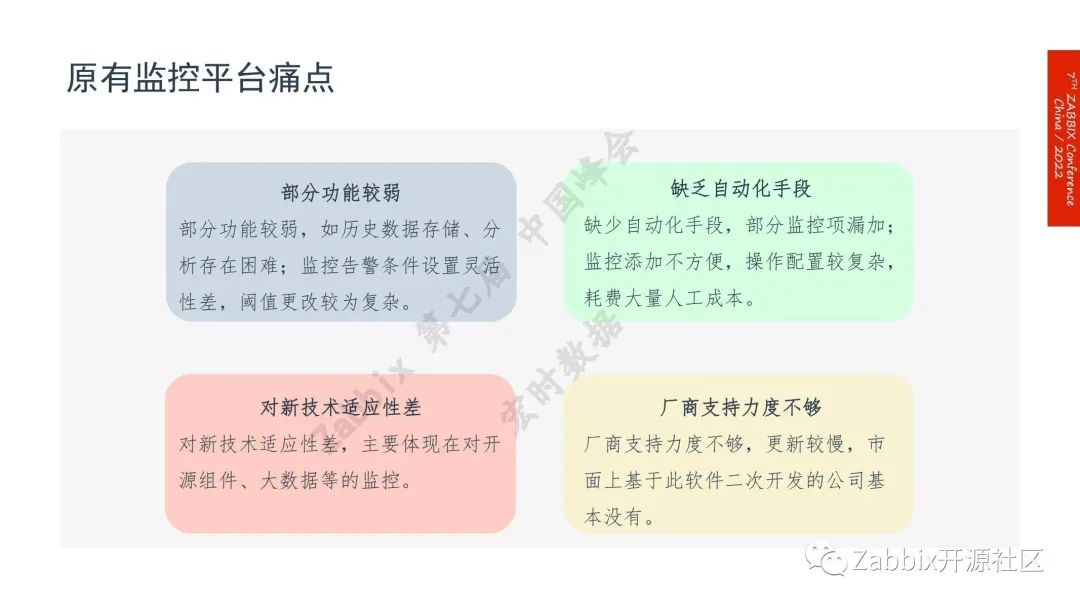
原有监控平台的痛点共有四个方面:
1.部分功能较弱
2.缺乏自动化手段
3.对新技术的适应性差
4.厂商支持力度不够。
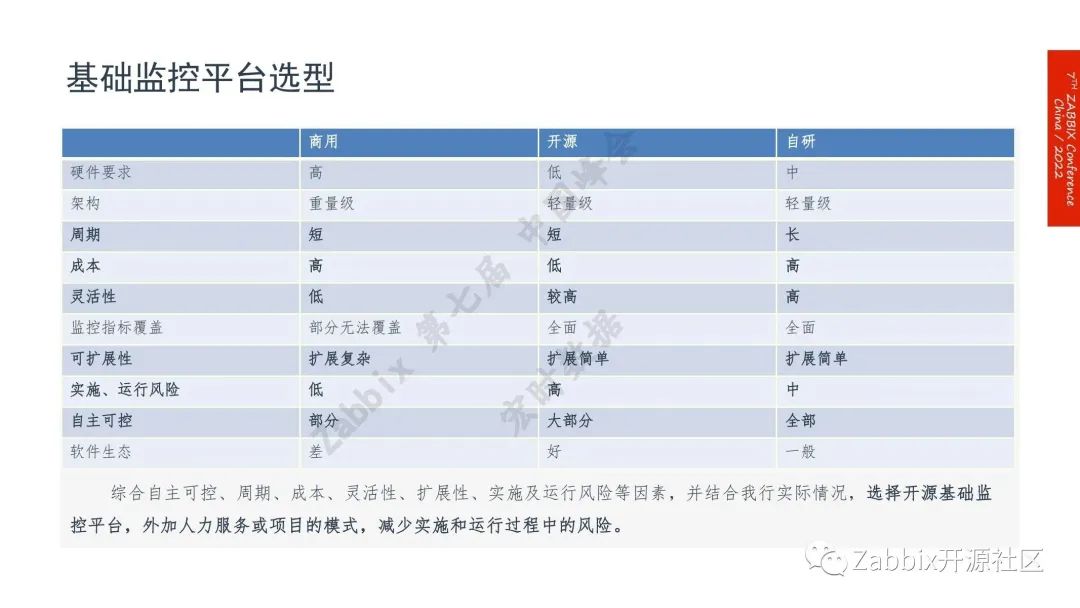
基础监控平台的选型:综合自主可控、周期、成本、及运行风险等因素,并结合我行的实际情况,选择开源基础监控平台,外加人力服务或项目的模式,减少实施和运行过程中的风险。
通过比较和选型,我们选择Zabbix做为一个基础监控平台,优势如下:
Zabbix能完全满足对于基础监控品的需求;
Zabbix功能性、架构体系、服务体系可以媲美商业基础监控软件;
Zabbix在国内有完善的服务支持渠道和培训支持体系;
Zabbix解决方案,社区版和收费版无区别。
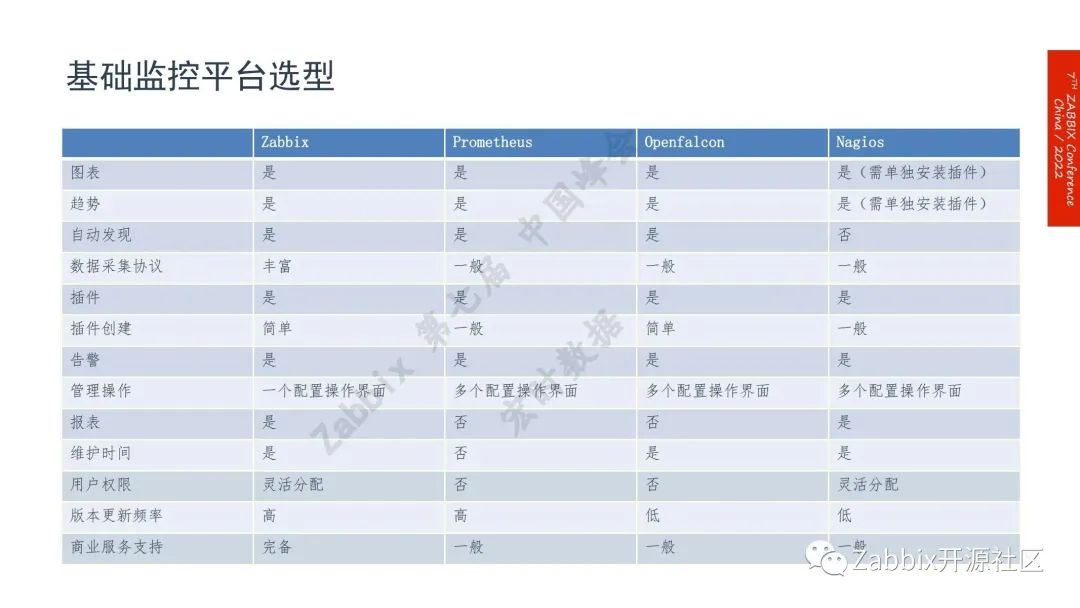
Zabbix监控平台建设阶段共分为4个阶段:调研、建设、深化和拓展。
建设阶段,搭建了Zabbix的技术监控平台、统一事件平台、智能分析平台;
深化阶段做了平台的对接并完善了平台的基本功能,目前完成了新老基础监控平台的迁移;
探索阶段是在逐步探索智能分析,系统根因分析、故障自愈等自动化的运维场景。
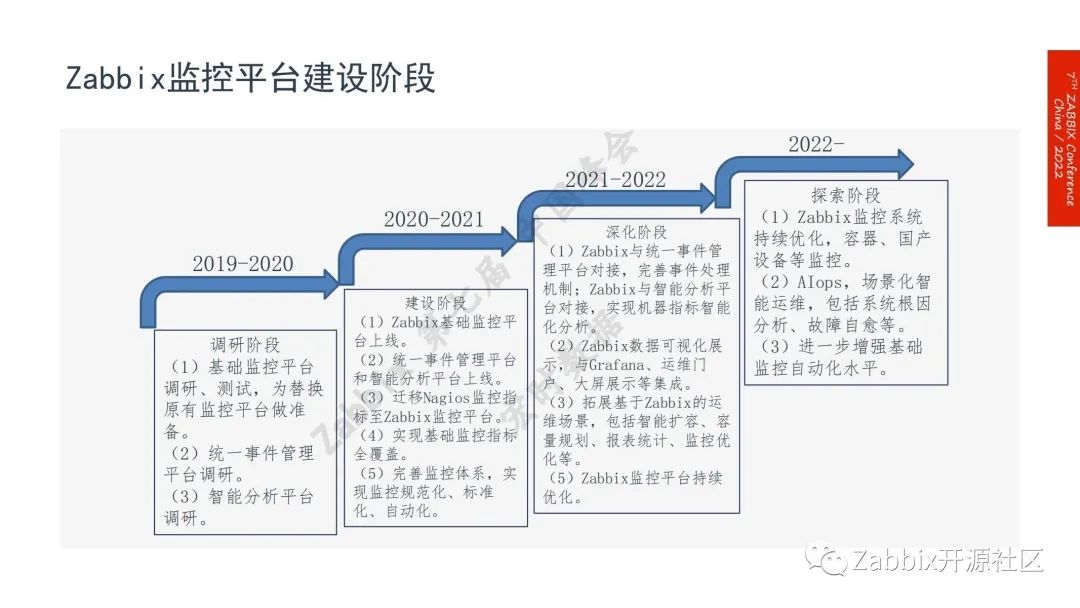
基础监控平台项目的收益
1.实现了基础监控指标的全覆盖;
2.实现基础监控的规范化、标准化和自动化;
3.提高运维效率,解放运维生产力;
4.提升数字化运营水平和安全运营水平。
Zabbix实践经验分享
Zabbix实践经验的分享,这是Zabbix监控平台的架构设计。整体上我们采用Server proxy分布式架构,监控对象是连接多个proxy,server是采用单组主被动模式,数据库则采用双组的数据复制的模式,然后通过table level组件实现在server和数据库的故障无缝切换,中间是Zabbix跟其他系统的对接,通过export、API以及SQL语句等多种方式来实现。
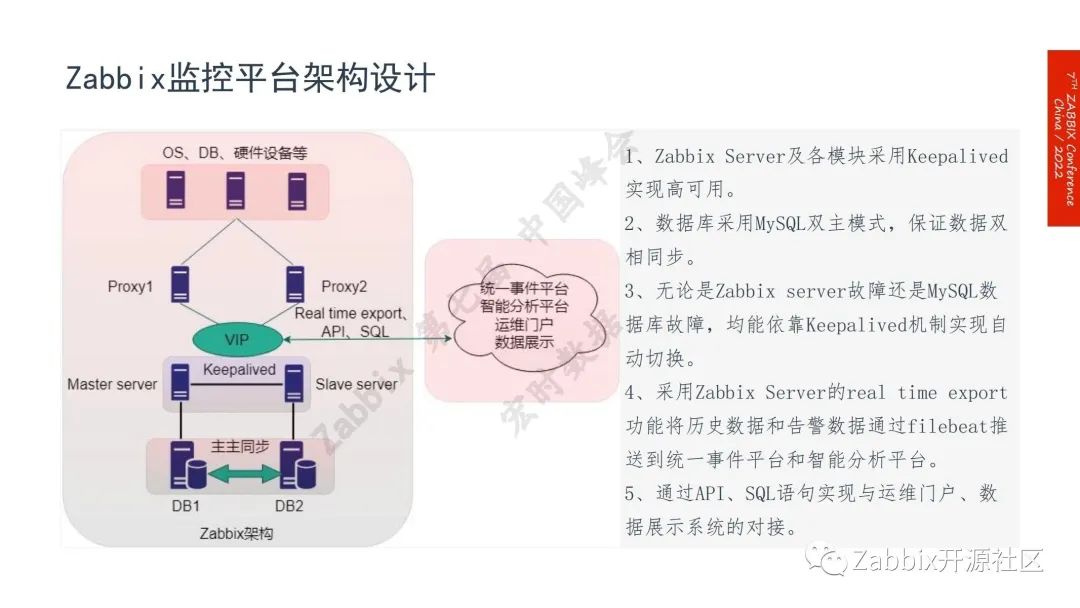
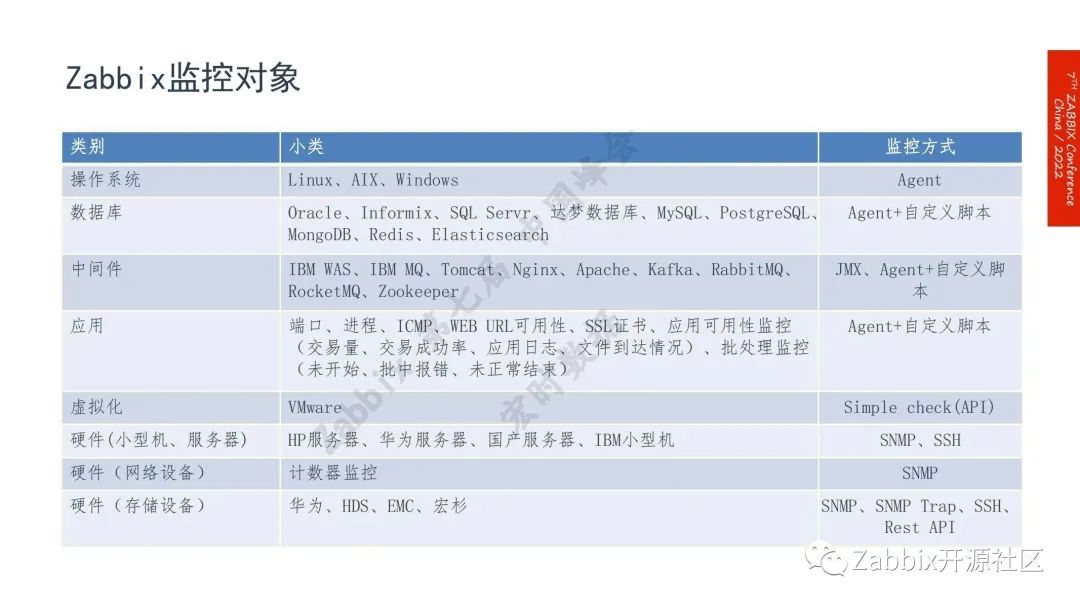
目前Zabbix的监控对象:包括操作系统、数据库、中间件和硬件设备等。监控对象是的非常全面,其中操作系统、数据库、应用、都采用agent自定义脚本的方式,中间件是采用JMX、agent自定义脚本来实现,VMware使用Zabbix自带的监控模板,服务器跟网络设备采用SNMP协议进行监控,存储设备的监控协议较多,包括SNMP、SNMP Trap、SSH、 Rest API等等。
生产的现有监控规模,主机9,500多台,监控项58万,触发器36万,Proxy4种模板有98个,用户数64个。众多主机、巨量的监控项,实际上生产的NVPS是1,800,如按照NVPS的十倍计算是18,000,主机监控9万台主机规模是很庞大的。

Zabbix实践经验分享——生产故障案例
生产的服务器光模块常出问题,有时重启也无法解决问题,两种情况:
1.彻底的损坏,失去链路冗余,有一定的运行风险;
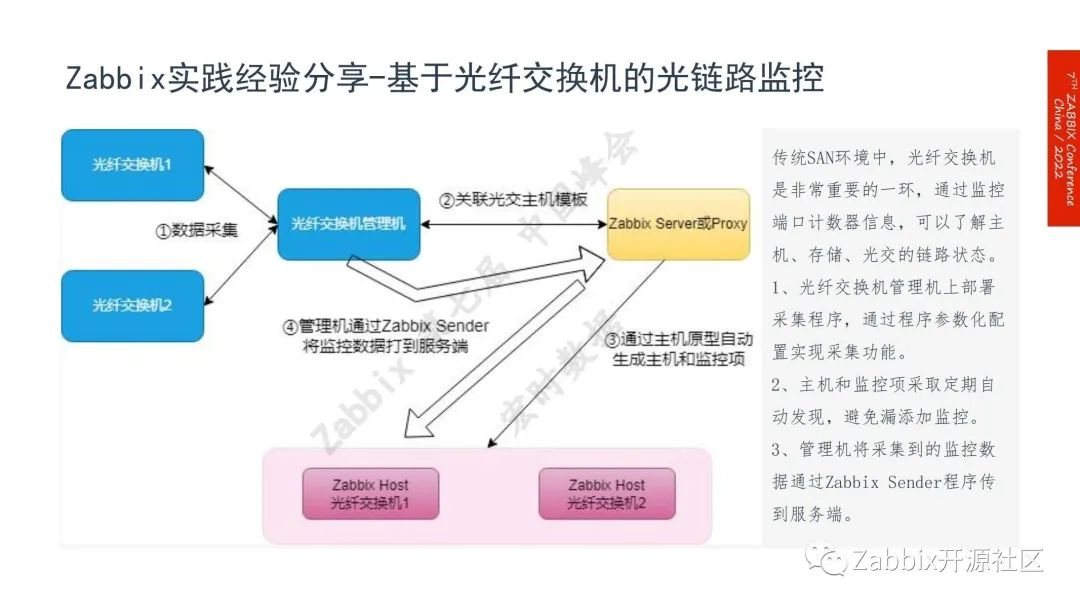
2.超时,造成业务运行缓慢,解决方法是:通过光纤交换机来监控主机和存储的光链路,专门有一台光纤交换机的管理机部署采集程序,管理机关联相关的模板就可以全自动发现主机和监控项,管理机将采集到的监控数据通过Zabbix Sender工具送达服务端实行监控告警。
Zabbix是很好的工具,大家可以在自己日常的监控中灵活使用。
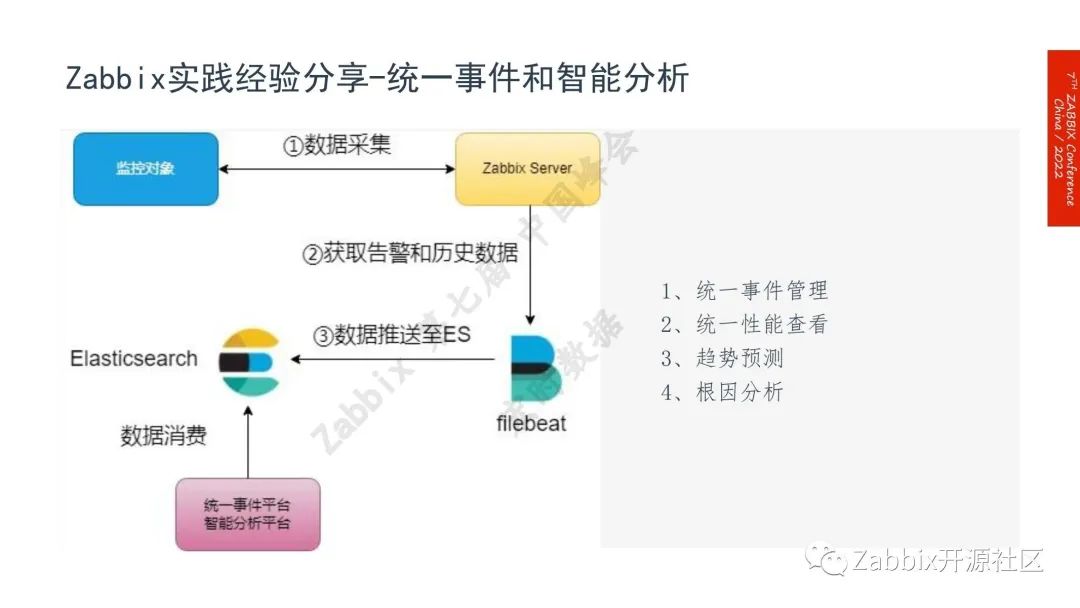
Zabbix对接统一事件平台和智能分析平台实现统一报警管理、趋势预测和更新分析。将采集到这个数据利用架构设计Zabbix Server的real time export功能(实时导出),通过Filebeat实时推送到ES中,提供统一事件平台和智能分析平台来消费,这是一个整体流程。
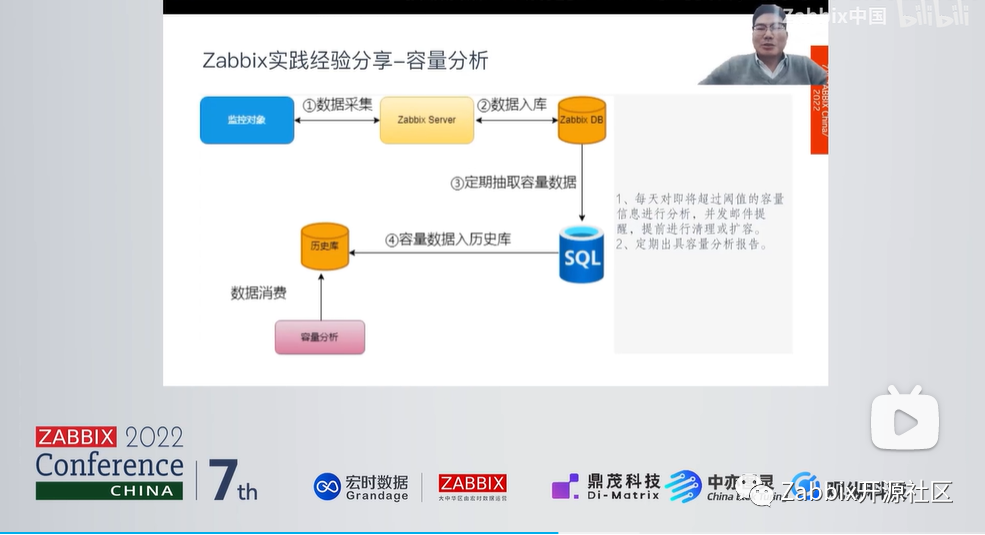
容量分析
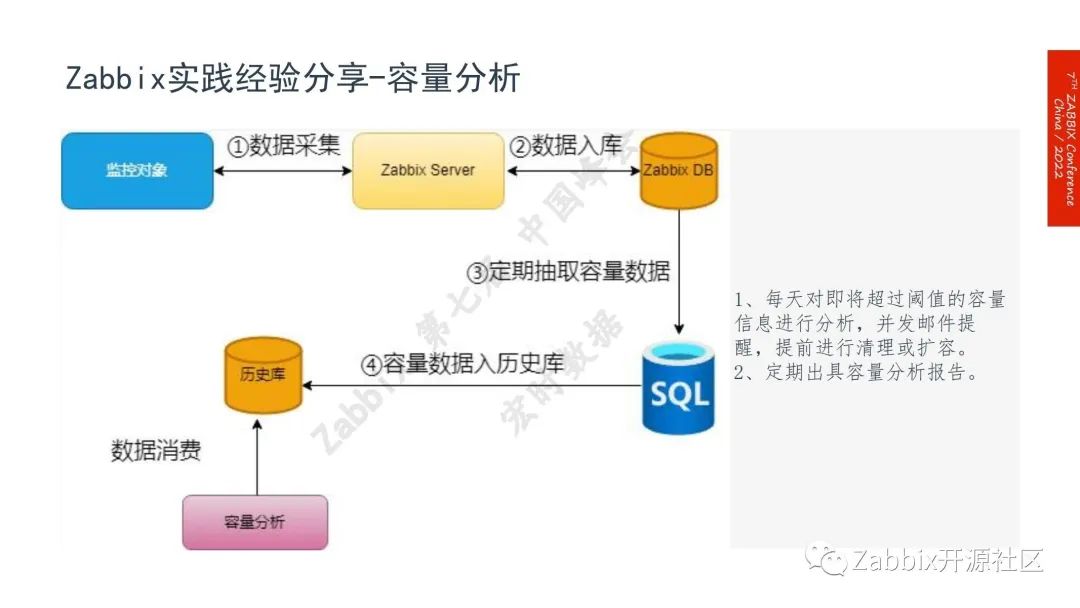
首先采集监控数据,将数据入库,通过SQL语句定期抽取容量数据,放到历史库中。如:虚拟机在Zabbix中显示的是实时虚拟机的信息,从这个层面上历史库是必要的,可以使数据保存的时间更久,后续能更好地进行分析。目前容量分析有两个场景:
1.每天对即将超过阈值的容量信息进行分析,并发送邮件提醒,提前进行清理和扩容。如此便不会被值班电话吵醒;
2.容量分析报告。通过容量分析报告避免抓瞎,明年该买多少服务器该买多少存储,这种困扰我们已久的问题都可以解决。
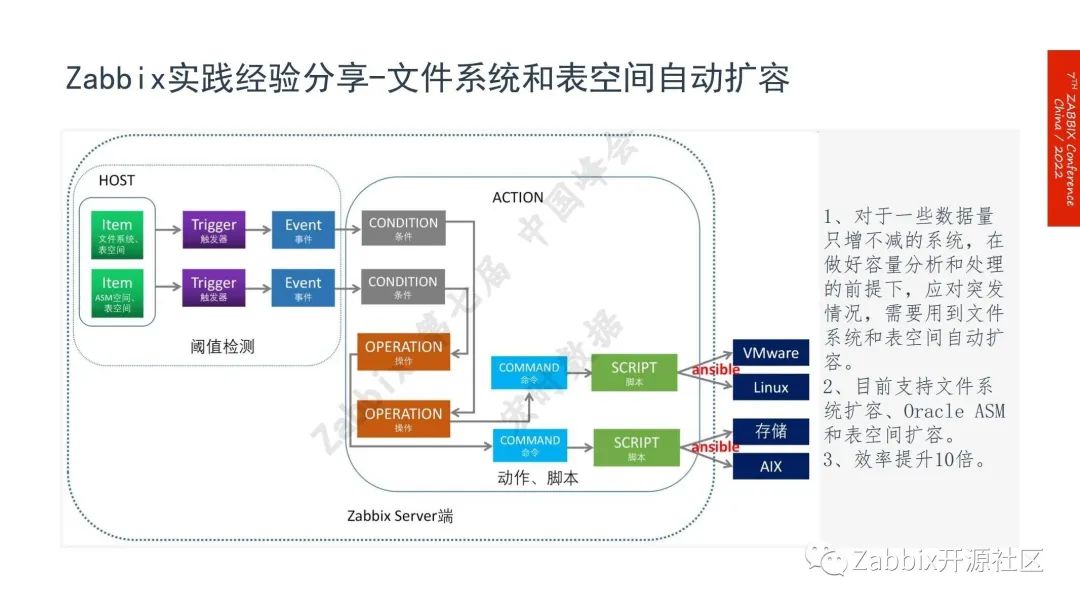
文件系统和空间自动扩容——故障自愈。自动扩容的机制是采用Zabbix强大的故障检测、动作执行的能力。当检测到操作系统的文件系统数据库的ASM磁盘空间、Oracle的数据表空间的使用达到一定的条件的阈值,便触发脚本动作,通过SSH的协议,对接存储设备,VMware平台以及操作系统,实现存储分配,磁盘识别、添加等操作最终实现文件系统和表空间的真空。目前生产实践过ASM扩容30秒左右,表空间文件系统的扩容在10秒以内,效率提升至少10倍以上。

统计报表通过Grafana来展现,展现内容:CPU的使用率的告警次数、内存使用率告警次数、SWAP空间使用率告警次数,TOP 100告警排名等等,统计报表数据大多通过SQL语句从数据库中取。此外还有操作系统统计,软件版本统计等等只要把SQL语句写出来就可以找到数据。
关于Zabbix数据库表结构的分析可以从用户Debug mode、官方文档API参考、Zabbix数据库创建 语句、Zabbix源码等途径进行分析,以达到写出想要的SQL语句的效果。
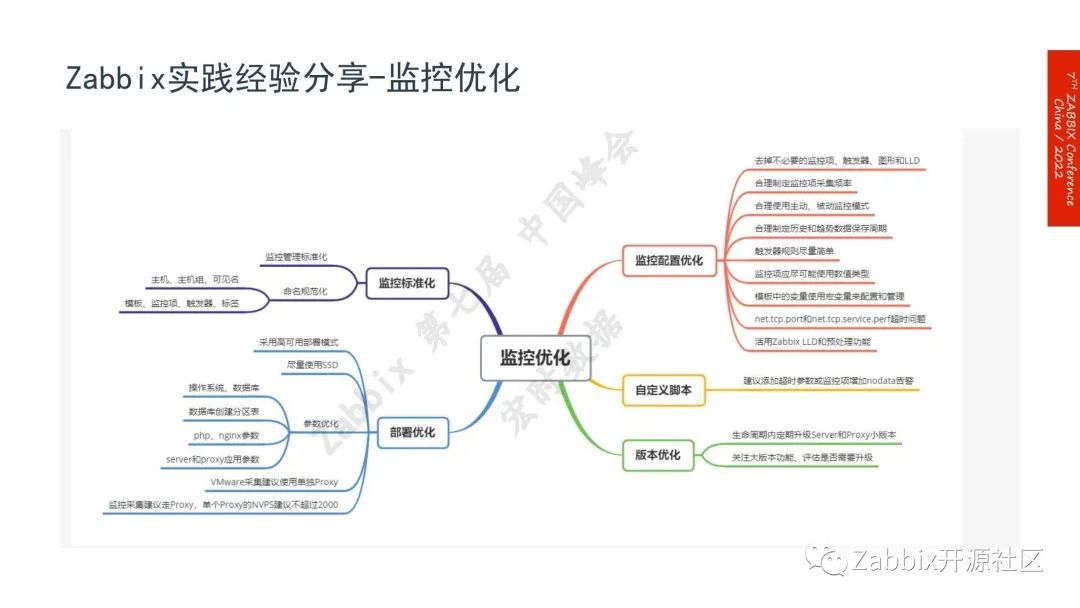
实践经验分享——监控优化
1.监控配置优化,包括去掉不必要的监控项、触发器、图形和自动发现规则,合理制定监控项的采集频率,合理使用主动被动的模式,合理制定历史和趋势数据的保存周期,触发器规则应该尽量简单,监控像尽可能使用数词的类型,模板中的变量使用宏变量来配置管理。当端口监控的超时,经过配置优化以显示Zabbix LLD和预处理的功能;
2.自定义脚本。建议在脚本里面添加超时参数或者增加nodata告警,对于这种超时现象需要及时发现。
实践经验分享——版本优化
1.生命周期内定期升级Sever和Proxy的小版本.在生产中遇到过以下故障:当时是5.0.4版本,故障为数据偶尔出现丢失,自己查了好久也跟官方这边联系帮着查找,一直没有查出什么原因,最后实在没办法升级了小版本,升级完之后就解决掉了;
2.需要关注大版本的功能,评估是否需要进行升级。监控的标准化,包括监控管理的标准化,命名的标准化、部署的优化,部署优化相对较多,包括采用高可用部署的模式,使用SSD以及数据库以及参数的优化。
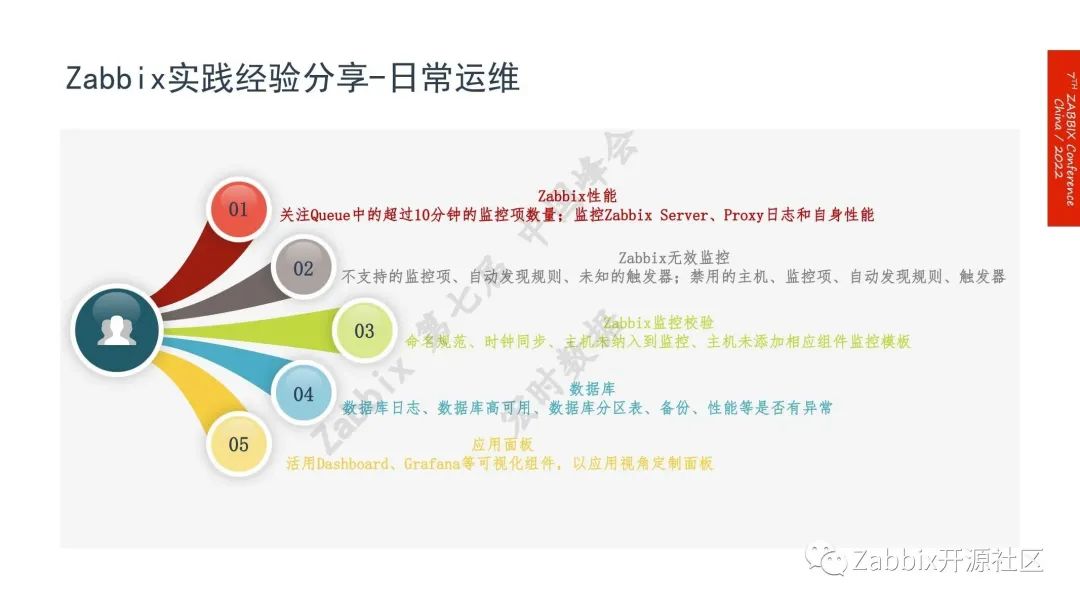
Zabbix实践经验分享——日常运维
1.Zabbix的性能,需要经常关注队列中超过10分钟的镜像的数量,做好监控Zabbix Server Proxy日志和自身的性能,使用Zabbix官方有相关的模板;
2.Zabbix的无效监控。包括不支持的监控项、自动发现规则、未知的触发器;禁用的主机、监控项、自动发现规则、触发器等;
3.Zabbix监控校验,包括命名规范、时钟同步、主机未纳入到监控、主机未添加相应组件监控模板等等,需要进行校验;
4.数据库。需要经常关注数据库的状态,包括数据库日志、数据库高可用、数据库分区表、备份、性能等是否有异常;
5.应用面板。活用Dashboard、Grafana等可视化组件以及应用视角定制面板。
对未来监控的展望
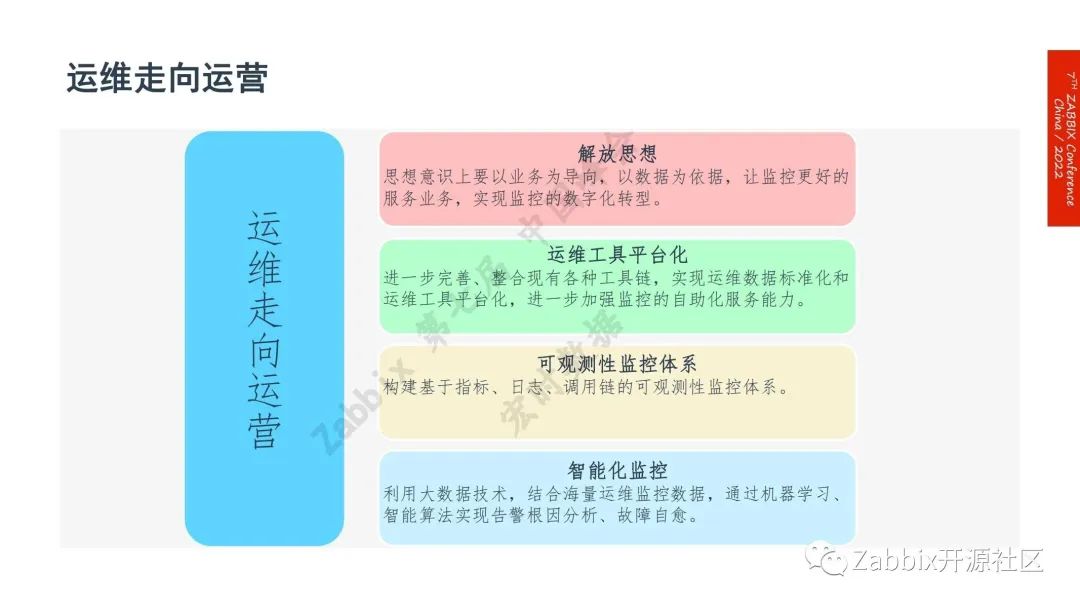
对未来监控的展望——从运维走向运营
1.是解放思想,思想意识上要以业务为导向,以数据为依据,让监控更好的服务业务,实现监控的数字化转型;
2.运维工具平台化,进一步完善、整合现有各种工具链,实现运维数据标准化和 运维工具平台化,进一步加强监控的自助化服务能力;
3.可观察性监控体系。构建基于指标、日志、调用链的可观测性监控体系;
4.智能化监控。利用大数据技术,结合海量运维监控数据,通过机器学习、 智能算法实现告警根因分析、故障自愈。
我的分享到此为止,ppt在公众号回复ppt获取。谢谢大家。
延伸阅读
Zabbix 6.4 惊喜发布!让管理Zabbix配置比以往任何时候都更加容易!新功能速查!

扫一扫|加入技术交流群
微信号|17502189550
备注“使用Zabbix年限+企业+姓名”
5000+用户已加入!

一个人走得快,一群人走得远!
 2023-09-14
2023-09-14






