 Zabbix 下载
Zabbix 下载 Zabbix 手册
Zabbix 手册 Zabbix合作伙伴地图
Zabbix合作伙伴地图 成为我们的合作伙伴
成为我们的合作伙伴
 订阅系统登录
订阅系统登录案例|安信证券监控平台如何设计和实现?
“Tivoli理想情况下应该支持各层级的监控,实际情况却是各自建设自己的监控系统,遇到这么多问题,怎么解决?我们还要不要打造统一的监控平台?答案是毋庸置疑的,需要。”
——李俊平, 监控平台负责人,安信证券

本文整理自李俊平在2020Zabbix中国峰会的演讲,演讲ppt请在文末留言区获取。更多演讲视频可关注官方Bilibili账号主页(ID:Zabbix中国)。
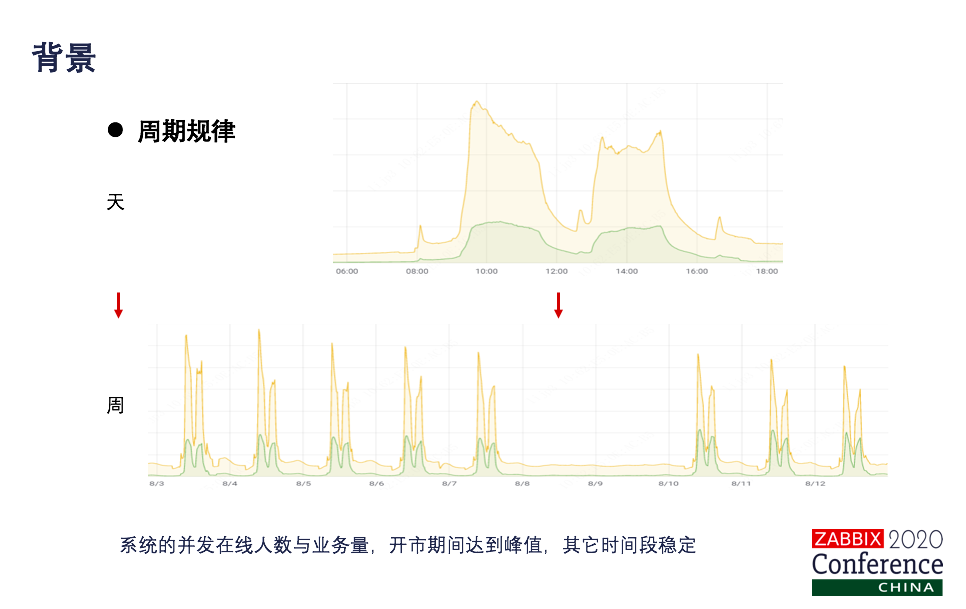
大家好,我分享的主题是安信证券监控平台的设计和实现,包含四部分:背景、演进、实现、展望。 背景 背景有四个方面:第一,既有传统应用也有互联网应用,系统部署方式有:集中部署、分布式部署、容器化部署、云上部署。第二,自研系统与外部系统异构并存,各系统还有关联关系,但技术栈、标准化程度不一样。第三,数据库种类多样,各类关系型数据库、NoSQL数据库都存在。第四,较多系统部署于Windows操作系统,比例接近50%。 券商特点:业务连续性、系统稳定性、安全性要求高,系统RTO、RPO期望趋近于0。事前预防,海恩法则:任何事故的发生之前一定有很多个征兆。做监控更多是做预防。墨菲定律:可能发生的一定会发生。提前介入进行系统巡检。 券商运维现在还呈现双态运维的一个特点,对于核心的业务,是采用稳态运维的方式,利用的是ITIL的一个模式。对于非核心业务,是采用敏态运维的方式,采用的是DevOps的模式。当然还有一个特点,我们是强监管的一个特性,以核心业务为例,就是RTO要求5分钟,RPO是30秒,超过这个时间系统就出现任何异常都要去上报证监局的。我们系统出现任何异常也好,领导第一句话就是问监控有没有提前发现,注意两个词,提前,事先有没有任何征兆?所以我们就很慌。所以说我们对“无监控不运维”体会非常深刻。 但是也不用怕,就从我们用波浪展示的图上看,虽然运维复杂程度很高,但是有规律可循。你可以看到我们正常情况下的业务量和在线人数都是在开售期间达到峰值。其他时间段基本上都是平稳的。
我们进行运维平台的建设,理想的情况是什么样子呢?是我们先制定监控管理的规范,标准化监控部署,采用自动发现的手段进行监控纳管,打造统一监控平台,加入AI,实现智能运维。但现实情况会有点不一样。为什么呢?
随着运维的不断深入,需求不断升级,做体系建设分层建设,但实践可能不允许。因为我们监控是并行建设的。其次我们打造监控平台,场景覆盖,理想情况下肯定是做需求调研,把所有的场景都调研到,但是可能吗?可能有小伙伴说可能,是的,那是理想情况。实际情况我们的工作场景会越来越多,可能不光服务于我们的应用场景,还会服务我们的业务场景。
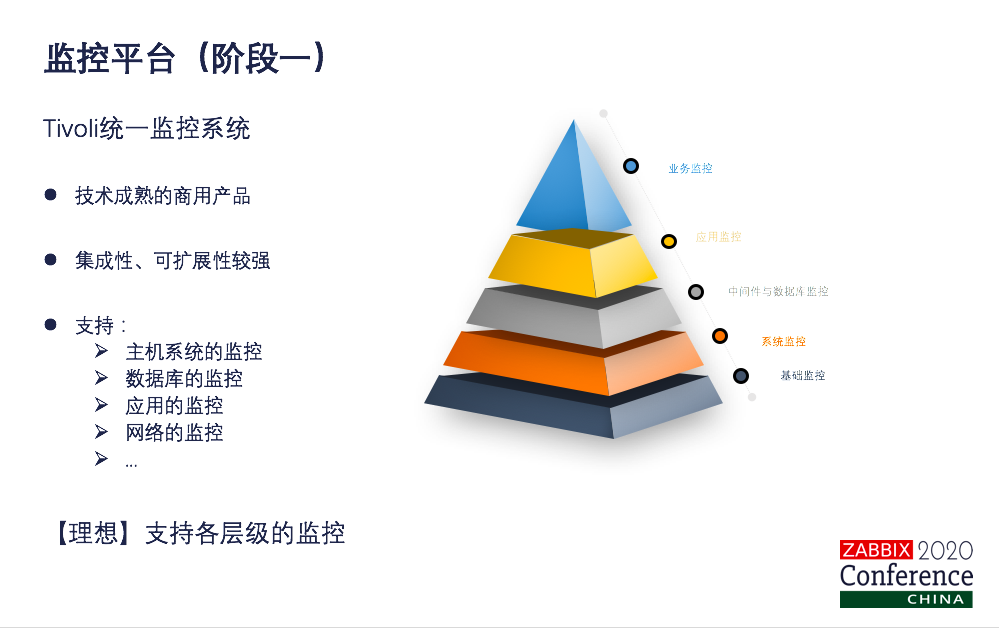
演进 随着我们技术的发展,现在应该有一个共识,就是监控平台不是一次建设就成功的,是需要持续演进的。打造持续演进的统一监控平台,看一下我们安信证券是怎么来进行演进的?首先小伙伴是不是都用过IBM的Tivoli,有的可能没接触过。恭喜你。如果你没用过,很好,你已经跳过这个阶段了,用过的你对我们会感受比较深刻。其实严格来讲,Tivoli作为一个成熟的商业产品,它在集成性、扩展性方面还是不错的,支持了主机系统、数据库、应用网络等等。从监控层级来说,应该是说支持了各层级的监控,这是理想情况。
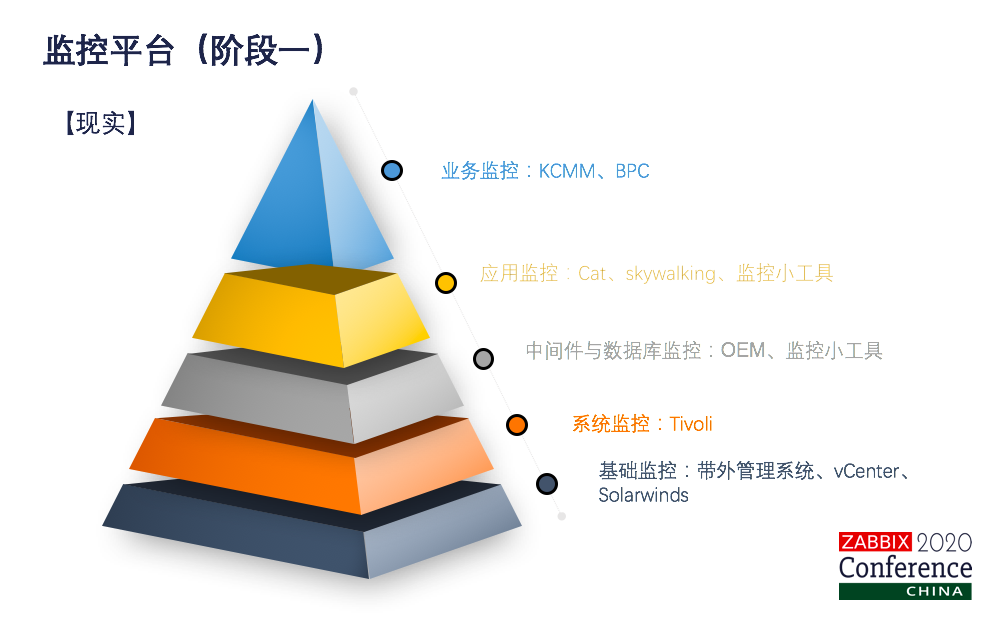
实际情况是这样的,为什么会产生这种现象?因为刚才讲了,无监控不运维。各个专业领域对监控的需求太旺盛了,他们也会各自建设自己的监控系统,物理机硬件的监控我们有带外管理系统,虚拟化监控有vCenter,网络监控有solarwinds,系统监控也统一打造成Tivoli,数据库监控用OEM,中间监控开发了一些资源的监控工具,应用监控有cat、有skywalking,也有资源的监控器,当然对一些外购的系统,因为我们三高的特点,一般都会带监控工具,业务监控就开skywalking,也有PPC等等。
遇到这么多问题,怎么来解决?我们还要不要打造统一的监控平台?答案肯定是毋庸置疑的,需要。我们分析为什么会产生这个原因?首先在这个阶段各个专业领域的监控工具发展是很迅速的,其实它是补充了我们监控的深度。第二Tivoli架构其实我们看的还是比较厚重的,应该说无法快速适应我们IT环境。总体来说Tivoli还是比较注重于这个基础架构,技术资源的监控,忽略了业务和应用的监控,它的异常告警的功能比较强大,但是性能分析这块相对来说比较弱。
看我们如何来解决呢?还是要打造统一的监控平台,但是要以模块化的方式来做一个架构,这些模块化要采用松耦合的方式。当然刚才说了我们异常告警功能比较强,所以我们保留它的核心的事件处理引擎。OMNIbus以我们快速发展的新旧监控工具进行深度的集成。第三Tivoli的界面大家用过的人可能也了解是用Java写的,但是应用性和美观看大家喜不喜欢了。我们是会对UI进行全面升级的,采用HTML5加Tivoli的方式,提供有现代感的仪表盘和大屏展示。关于业务应用监控这块,进行监控工具的集成,打造了统一的集中日志平台,来逐步提升业务和应用的监控。
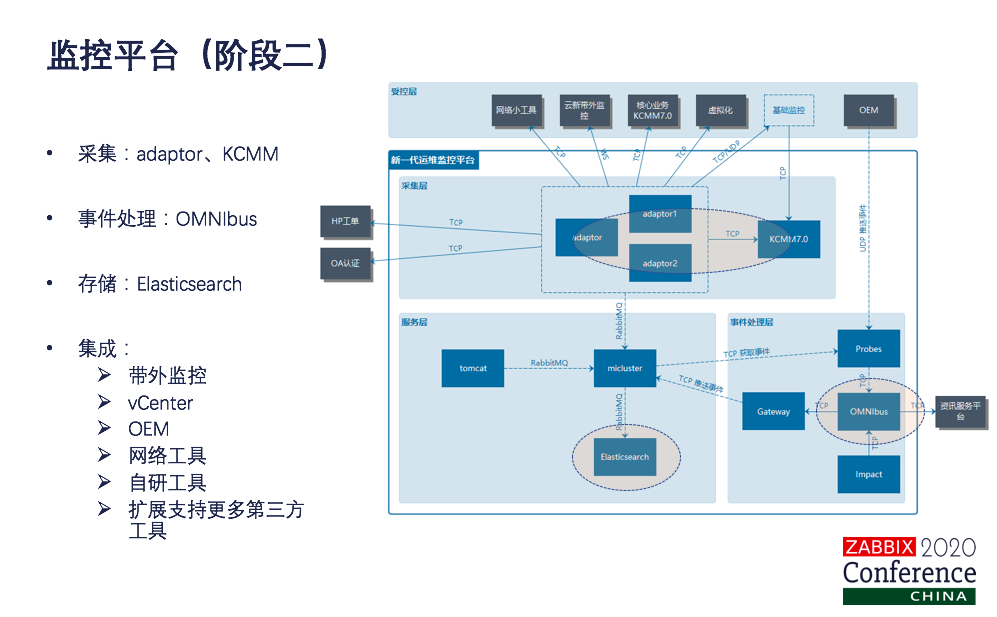
这是阶段二的统一监控平台的逻辑架构图,对于通用监控开发了一个adaptor,对通用资源的这些数据采集处理是用adaptor。刚才也讲了券商系统,windows的系统比例占比很大,还是保留了KCKK来进行监控,因为windows系统有很多是这种窗体界面的一些监控,还是保留KCMM。事件处理统一用OMNIbus。告警和现场数据统一存到Elasticsearch上面。对于专业领域是做集成工作,集成了带外、vCenter、OEM、网络工具、自研工具、cat、skywalking等等都进行了集成。当然我们是定义了标准化的接口。当然刚才也讲了我们做专业化的工具其实在这个阶段也在发展,我们这个平台就应该能快速支持更多的第三方工具。好了,这个阶段。ES、OMNIbus、adaptor是我们监控平台的核心。
可以说在这个阶段我们是打通了通用领域监控和专业领域的监控。从技术层面来看,应该是做到了统一,但是我们这套系统是要给业务人员应用的,实际业务人员在用的过程中发现,这个是做了统一了,但是好像以我这个工作,这场景的紧密程度还是不是那么够。体现在这几方面,第一点我们告警和性能关联性不强,一个监控系统,一个报警系统。第二点是我们开发的adaptor,告警的特点还是采用固定模板的方式,对一些复杂的场景还需要进行二次开发。性能展示的内容自助性也不高。当然还有一点,缺乏统一的资源配置信息。
遇到这些问题看一下我们如何来解决的。首先建立统一的监控portal,势在必行,这块最后会形成我们的运维门户。我们监控的一定要从用户的角度出发,而不是从技术的角度出发。技术是服务于业务的。第三点我们要以告警作为切入点,监控以我们的录制大数据、性能分析,拓扑可视化进行联动。第四点还是要采用实用的原则,不要重复造轮子,我们会引入开源的模块,能快速提供一些自助化的服务。当然我们配置信息其实从我们建好的CMDB里面就可以实现自动的同步了。 这是现阶段监控平台的整体架构。我们实现了统一监控的portal,集成了Grafana的数据展现服务,iCube日志管理服务,APM的业务性能管理服务,还有smartBI的报表服务等等。监控覆盖的对象包括系统应用、业务、数据库、中间件、网络等等,应该是说我们监控模型中的前站。对于通用的领域,我们引入了开放的Zabbix平台,进行数据的统一采集处理。刚才说了我们还是有部分系统是不存在windows平台的,KCMM得以保留,但是这块我们对它的性能和接口进行了升级,采用rsyslog的方式推送到Omnibus,高检的数据统一还是推送到Omnibus。性能促进我们这个都会推到我们的ES,最后的数据都汇总到应用大数据平台,做深度的数据挖掘分析。
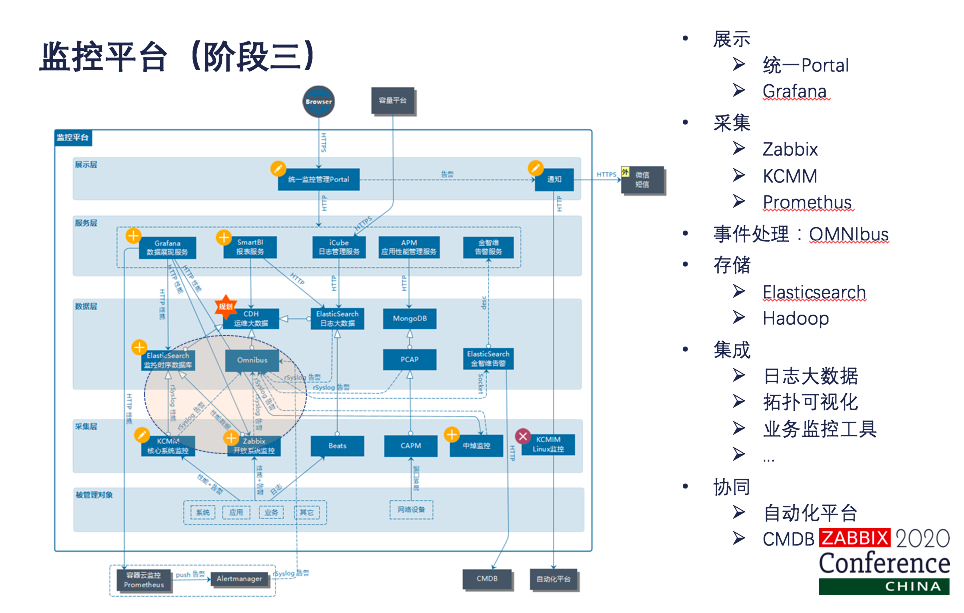
是不是漏了一块,容器监控怎么办?我们还是采用了开源的prometheus进行监控。对日志是采用了Beats的采集,数据处理最好要统一录到ES里面。当然在最后的数据都会用到大数据平台。刚才说了监控的对象是会发生变化的,怎么办?从我们打造统一的CMDB配置管理平台里面同步配置管理数据,当然监控还是会通过消费反向推动我们CMDB数据的标准化和准确性的。告警的数据也会触发自助化平台的作业,实现监控和自助化的联动。在这个阶段。ES、Zabbix、Omnibus还是这套系统的核心,不管以后是云商的监控,容器的监控,什么工具的变化都不影响我们整套系统的稳定性。

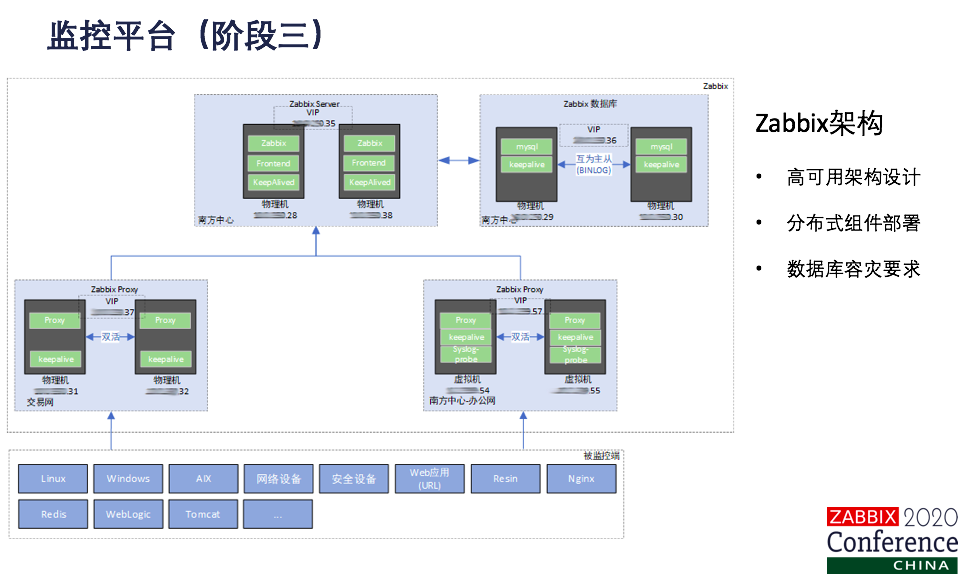
我们采用Zabbix用于通用云的监控,其实就覆盖了从技术监控到业务监控了在各个层级。Zabbix的扩展兼容性比较强,适合于统一监控的集成,当然也会分阶段来替换我们零星的一个监控工具。对于增量的系统和业务应用来说,我们是统一用Zabbix进行监控的。当然Zabbix的agent也会打到操作系统的镜像模板中。对于存量的系统,因为金融行业,不要那么快,我们还是要逐步迁移。Zabbix的监控模板比较丰富,我们对于需求比较旺盛的IPS、WAF的安全设备,快速的定制了模板实现了监控。当然对于中间件就是Redis,Nginx、Redis、Tomcat、Resin等等,我们也快速的定制了模板。
这是我们Zabbix采用高可用的架构部署方式,各个组件都是采用VIP、keepalive的方式实现HA的。我们在交易网、办公网、两地三中心各个环节都部署了多组的Zabbix proxy,数据库需要容灾要求,我们单独进行了部署。这块刚才我们在整体架构中可以看到,其实Zabbix都是实时和准时数据,这份数据最后都是推到ES里面,其实都是用我们的大数据平台来进行数据的分析处理的。
实现
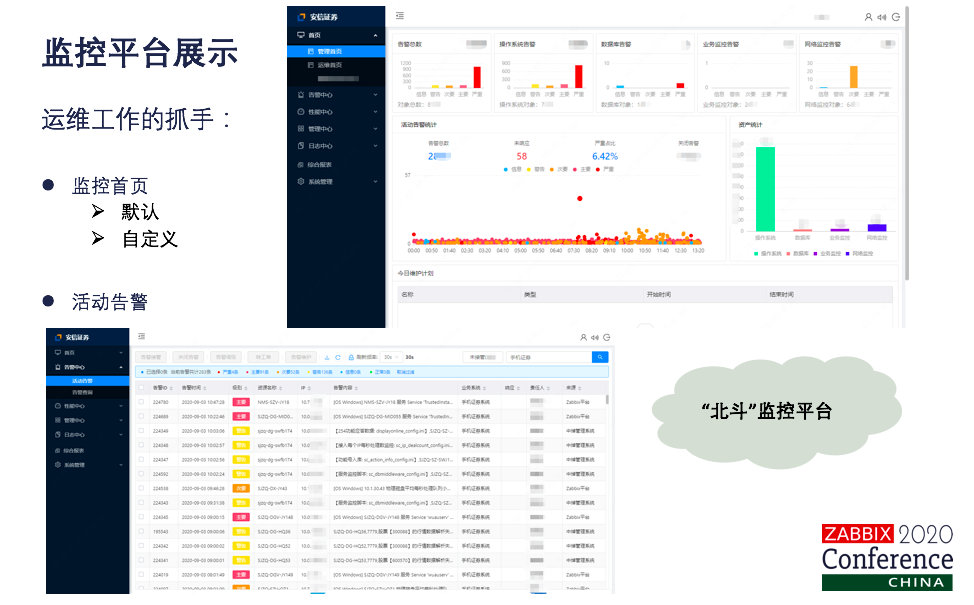
现在来看一下我们Tivoli监控平台具体的实现情况。首先这套监控平台是作为运维工作的抓手,定义了监控首页,默认的是有管理首页和运维首页。当然各个系统负责人也可以自己定义个性化的首页,以达到千人千面的效果。这里我把它屏蔽掉了,因为是我个人的定制。从管理首页我们可以看到,我们可以有资产统计信息,有告警的总数、分项,还有我们活动告警的时间、散点分布图,还有我们的维护器计划等等,都集中在首页。业务人员或者是系统管理员只要看到首页页面就够了。当然了,监控最主要的工作是告警。在活动告警页面可以看到,对于一套系统来说,有来源于Zabbix监控的,有来源于专业领域综合监控的,有来源于其他相关的一些监控系统的,但是在我们北斗监控平台,大家能看到Zabbix的影子吗?看不到。能看到prometheus的影子吗?看不到。但是我们就是做这样一份工作,这就是我们的运维监控平台。 正常的日常工作的场景,其实还是要以告警作为切入点的。其实还是以使用的原则,直接右键就可以查看我们告警上下文日志,性能情况,拓扑图情况。这是我们北斗监控平台基于运维工作场景的一些集锦图,我们点开一个告警可以看到它对应的原始日志和格式化日志,以便进行详细的问题分析。这块是关联影响分析,可以看到告警的主体所在的部署架构拓扑图。当然通过grafana定制了很多这种系统的仪表盘用于系统的巡检。在性能趋势分析,是打通了告警和性能数据的展示。当然了对于Zabbix用户来说,也提供了延伸监控数据的展示,Dashboard、Graph都可以。通过Zabbix通用数据采集,Grafana整体数据展示,实现了就说1+1大于2的效果。可以看出其实已经实现了系统中间件、应用、业务各层级的监控。 打造了统一的监控portal,接下来我们怎么做? 其实北斗监控平台,或者是要打造监控平台,不光应该是指服务于运维人员的,应该把这个平台推广出去,服务于我们的研发人员,更要服务我们的业务人员。其实对运维人员来说,对监控平台很熟悉了,通过监控来了解系统状态,容量情况,发现系统异常,恢复业务连续性,预防故障,实施部署扩容工作,这都是业务人员经常要做的事。研发人员要怎么呢?要通过我们这个平台能做什么呢?发现系统各服务和应用组件的历史性能趋势,实施架构和代码优化工作。对业务人员,业务人员是最关注的。是要通过我们监控掌握我们业务的当前运转情况,客户的实际体验,基于这些信息展开一些针对性的营销活动。
展望
期望我们的北斗监控平台成为运维人员的传感器,研发人员的指南针,业务人员的工作小助手,这是基于工作场景规划的整体的IT运维平台。我们监控在这一块。对我们监控平台持续进行优化改进,要打造成监、管、控、营四位一体的IT运维平台。
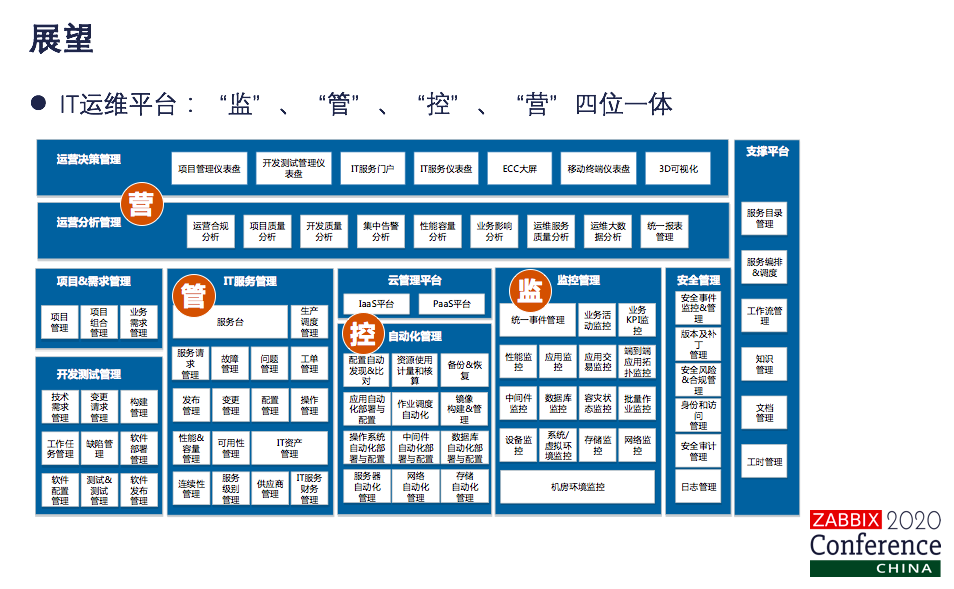
刚才我们也讲了,理想的情况下是先进行标准化工作,后面来进行运维平台的建设。运维监控平台在实际建设是反向推动我们业务工作的标准化的。第二点,我们经过了三次的演进,因为统一的运维监控平台,还需要提供更多的自助化的服务,为运维赋能,同时运维监控的数据落到运维大数据平台,我们要进行深入发掘和数据的分析,探索运维数据的价值落地,要按照标准化、平台化、一体化、智能化的方向继续前行。
谢谢大家。ppt可在文末留言区获取。
2021在线课第一节课将于本月29日开课!思德结合自身使用经验和群内用户的提问,设计如下课表。线上直播上课,互动性更强,欢迎提问交流。
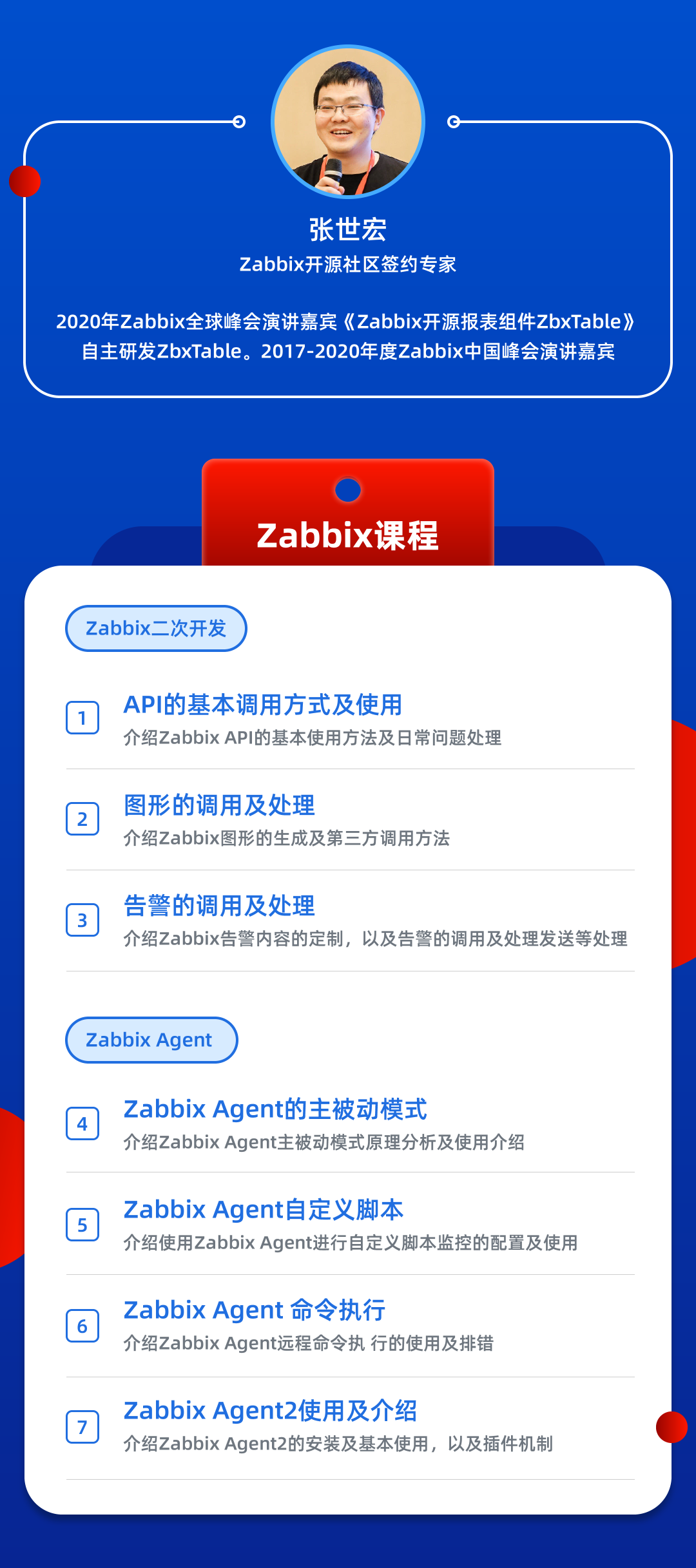
在线课不仅包含专家系列课,还有官方主题课,课表见报名链接。
关注公众号 干货满满 加入交流群 3000+用户已加入


 2023-04-26
2023-04-26






